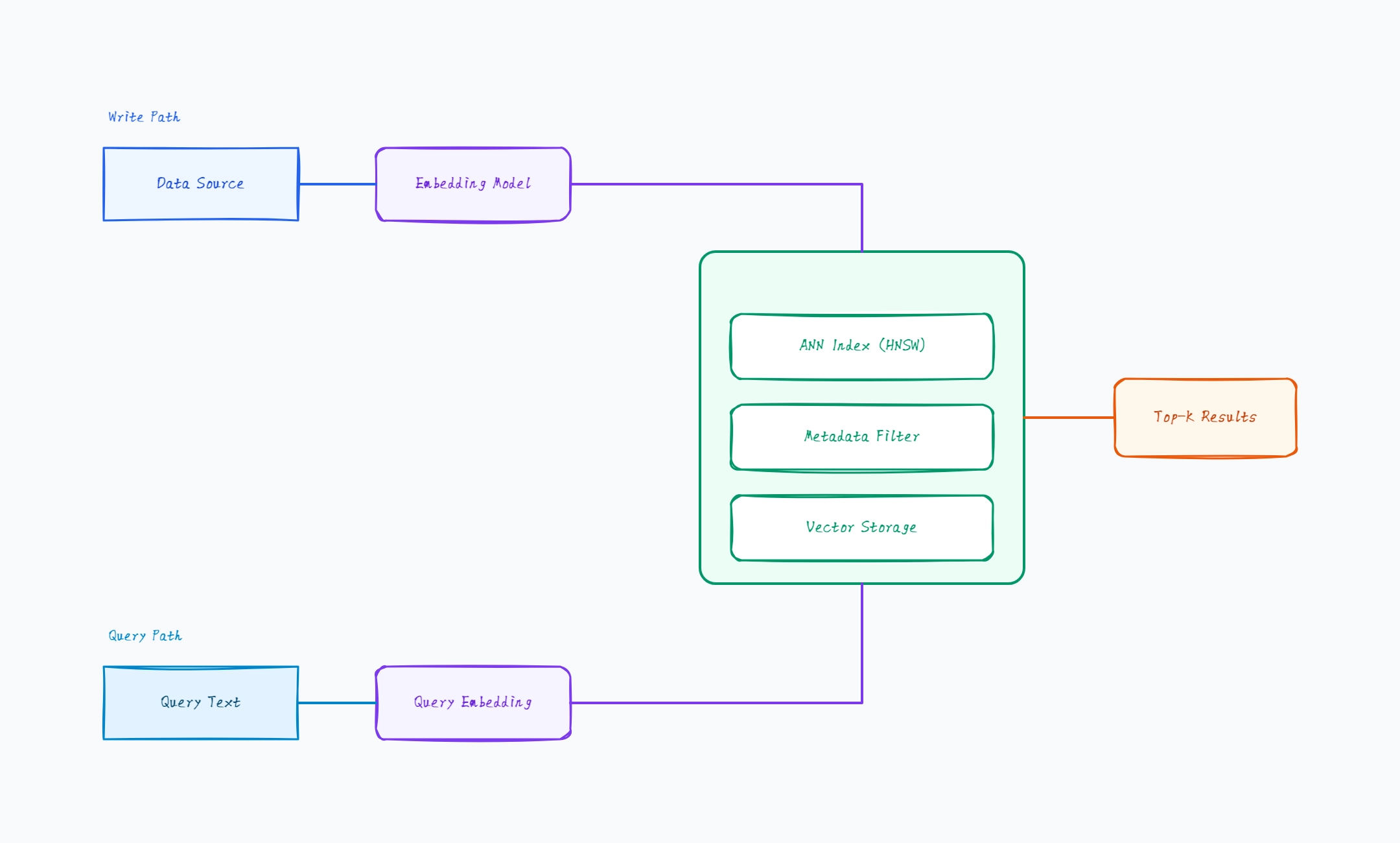
Managed vector database (Pinecone-style)
Who uses it: Developer who wants vector search without running infrastructure
App calls a managed API for upsert and query
Index, storage, and scaling are handled by the provider
Metadata filters supported alongside vector similarity
Embedding model runs in the app, not the database
Namespaces isolate tenants within one index
Why this works: A managed vector DB is the fastest path to production — the diagram is simplest because index, storage, and scaling collapse into one provider box, leaving you to own only the embedding step.
Self-hosted (pgvector / Qdrant)
Who uses it: Team keeping vectors next to existing relational data
Vectors stored in Postgres via the pgvector extension
Same database holds relational rows and their embeddings
ANN index (IVFFlat or HNSW) built on the vector column
SQL WHERE clauses double as metadata filters
One database to back up, secure, and operate
Why this works: Self-hosting with pgvector wins when vectors belong with existing data — the diagram folds vector storage into your primary database, so there's no separate system to sync, at the cost of managing ANN tuning yourself.
Hybrid search
Who uses it: Team where pure vector search misses exact terms
Query runs against both an ANN index and a keyword index
Dense (embedding) + sparse (BM25) results are fused
Reciprocal Rank Fusion merges the two rankings
Metadata filters applied before fusion
Single response combining semantic and lexical matches
Why this works: Hybrid search adds a keyword index beside the ANN index — the diagram shows two retrieval paths converging at a fusion step, which is how you catch exact terms (codes, names) that pure embeddings miss.
Sharded at scale
Who uses it: Team with billions of vectors beyond one node
Vectors partitioned across multiple shards
A router fans a query out to all shards in parallel
Each shard runs ANN search on its partition
Results merged and re-ranked into a global Top-K
Replicas per shard for availability
Why this works: Sharding is unavoidable past a single node's memory — the diagram adds a router and a merge step, because at billions of vectors the architecture is as much about scatter-gather as it is about the ANN index itself.