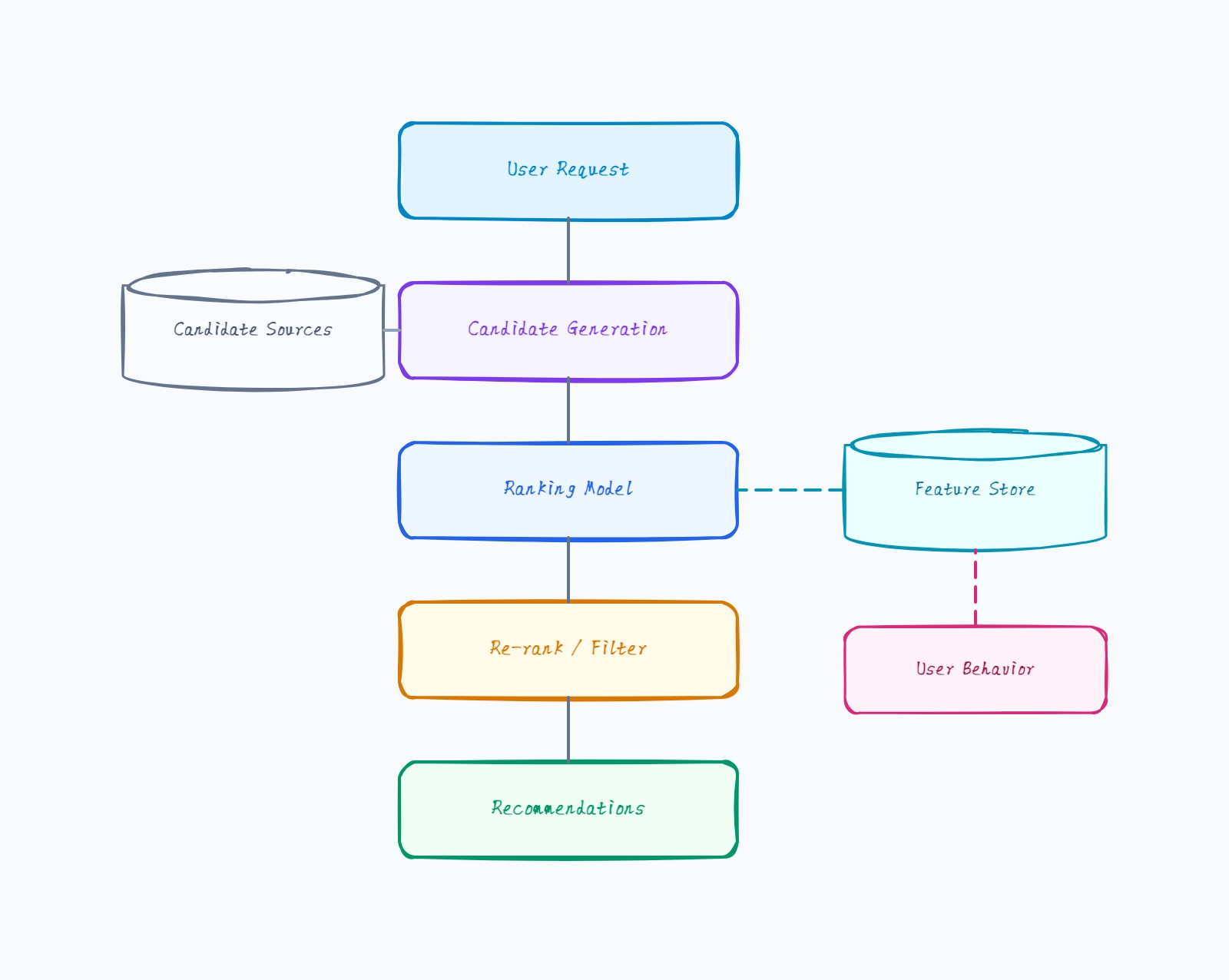
Collaborative filtering (the baseline)
Who uses it: Developer building a first recommender
Candidate generation: user-item matrix factorization
Recall: items liked by similar users
Ranking: a simple gradient-boosted model on basic features
Re-rank: filter already-seen items
Cold-start handled by a trending fallback
Why this works: Collaborative filtering is the classic starting point — the diagram's recall stage finds items that similar users liked, which works well once you have interaction data but needs a fallback for new users and items.
Two-tower retrieval
Who uses it: Team scaling recall to millions of items
User tower and item tower produce embeddings
Recall = approximate nearest neighbor search over item embeddings
Item embeddings precomputed and indexed (a vector DB)
Ranking model re-scores the top-N retrieved items
Towers retrained as behavior shifts
Why this works: Two-tower retrieval scales recall by turning it into a vector search — the diagram adds an embedding index, because scoring every item is impossible at scale, so recall becomes ANN lookup over precomputed item vectors.
Real-time recommendation
Who uses it: Team serving recommendations with fresh signals
Streaming features updated from live user events
Online feature store (low-latency) for ranking
Recall mixes precomputed candidates with session items
Ranking runs per request within a tight latency budget
Behavior streamed back to update features in seconds
Why this works: Real-time recommenders add a streaming feature path — the diagram splits the feature store into online and offline, because the latest in-session behavior must reach the ranking model within the request's latency budget.
LLM-based recommendation
Who uses it: Team using an LLM to rank or explain recommendations
Recall stays traditional (retrieval over items)
LLM re-ranks candidates using natural-language context
User intent expressed as a prompt, not just clicks
LLM generates explanations for each recommendation
Embeddings bridge items and the LLM's context
Why this works: LLM-based recommenders usually keep traditional recall and put the LLM in the ranking/explanation stage — the diagram shows the LLM re-ranking a retrieved shortlist, because running an LLM over the full catalog would be far too slow and costly.