Single replica (the baseline)
Who uses it: Developer deploying a first model endpoint
One inference server behind a simple reverse proxy
Model loaded once at startup from the registry
Synchronous request → predict → response
No batching; one request at a time
Basic health check and latency logging
Why this works: A single replica is the simplest serving setup — the diagram has no batch queue or load balancer because one server handles requests serially, which is fine for low traffic but can't scale or batch.
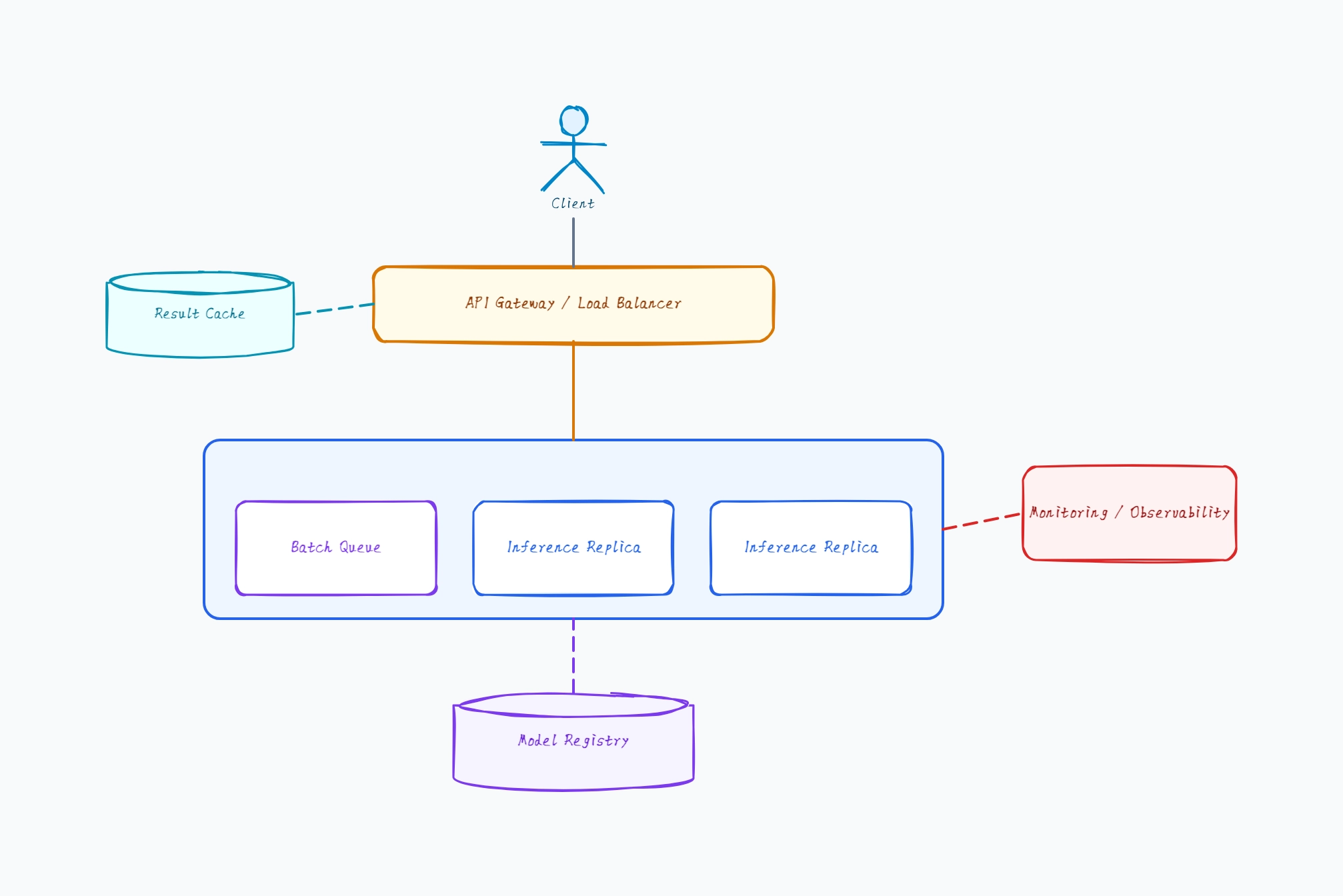
Autoscaled cluster
Who uses it: Team serving variable production traffic
Load balancer distributes across N replicas
Batch queue groups requests for higher GPU throughput
Autoscaler adds/removes replicas based on queue depth
Shared model registry; replicas pull the same version
Monitoring drives the autoscaling signal
Why this works: An autoscaled cluster is the production-standard serving pattern — the diagram adds a batch queue and autoscaler because batching maximizes GPU efficiency and autoscaling matches replica count to load.
Multi-model server
Who uses it: Team serving many models from one fleet
One serving framework hosts multiple models (Triton, TorchServe)
Gateway routes by model name to the right backend
Registry holds all model versions; replicas load on demand
Per-model batching and versioning
Shared monitoring across all models
Why this works: A multi-model server consolidates many models onto shared infrastructure — the diagram adds model-name routing at the gateway, so one fleet serves many models instead of one deployment per model.
LLM serving
Who uses it: Team serving large language models
Continuous batching (in-flight) instead of static batches
KV-cache management for in-progress generations
Token streaming back to the client
Replicas sharded across GPUs for large models
Specialized server (vLLM, TGI) instead of generic serving
Why this works: LLM serving replaces static batching with continuous batching and adds KV-cache and streaming — the diagram reflects that generation is token-by-token, so the serving layer must manage in-flight sequences rather than discrete request-response pairs.